

Справка по работе с ApiRouter GPT
Пользователи нашего сервиса могут работать как через мобильное приложение (доступно в RuStore), так и через веб-версию по адресу: https://app.apirouter.ru Для входа в обе версии используется один и тот же логин…
Управления API ключами для работы с нейросетями. GPT-4, Claude, Gemini, Llama и другие ИИ модели в одном месте. Контролируйте расходы, мониторьте использование
Идеален для сложных задач, аналитики и работы с большими объёмами текста.
Базовая цена: ~1 180 ₽ за 1 млн входящих токенов, ~5 900 ₽ за 1 млн выходящих токенов.
Подходит для ассистентов, общения, текстов и обработки документов.
Базовая цена: ~235 ₽ за 1 млн входящих токенов, ~1 180 ₽ за 1 млн выходящих токенов.
Идеален для простых задач, чатов и автоматизации поддержки.
Базовая цена: ~20 ₽ за 1 млн входящих токенов, ~98 ₽ за 1 млн выходящих токенов.
Отлично справляется с программированием и логическими задачами.
Базовая цена: ~0.63 ₽ за 1 млн входящих токенов, ~1.89 ₽ за 1 млн выходящих токенов.
Endpoint: POST /api/chat/completions
import requests
def chat_with_model(token):
url = 'https://app.apirouter.ru/api/chat/completions'
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json'
}
data = {
"model": "aion-labs/aion-rp-llama-3.1-8b",
"messages": [
{
"role": "user",
"content": "Как образуется снег?"
}
]
}
response = requests.post(url, headers=headers, json=data)
return response.json()
curl -X POST https://app.apirouter.ru/api/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1",
"messages": [
{
"role": "user",
"content": "Как скачать whatsApp"
}
]
}'
Endpoint: POST /api/v1/files/
Чтобы использовать внешние данные в ответах RAG, вам сначала необходимо загрузить файлы. Содержимое загруженного файла автоматически извлекается и сохраняется в векторной базе данных.
import requests
def upload_file(token, file_path):
url = 'https://app.apirouter.ru/api/v1/files/'
headers = {
'Authorization': f'Bearer {token}',
'Accept': 'application/json'
}
files = {'file': open(file_path, 'rb')}
response = requests.post(url, headers=headers, files=files)
return response.json()
curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Accept: application/json" \
-F "file=@/path/to/your/file" https://app.apirouter.ru/api/v1/files/
Endpoint: POST /api/v1/knowledge/{id}/file/add
После загрузки вы можете сгруппировать файлы в коллекцию знаний или ссылаться на них по отдельности в чатах.
import requests
def add_file_to_knowledge(token, knowledge_id, file_id):
url = f'https://app.apirouter.ru/api/v1/knowledge/{knowledge_id}/file/add'
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json'
}
data = {'file_id': file_id}
response = requests.post(url, headers=headers, json=data)
return response.json()
curl -X POST https://app.apirouter.ru/api/v1/knowledge/{knowledge_id}/file/add \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"file_id": "your-file-id-here"}'
Endpoint: POST /api/chat/completions
Вы можете ссылаться как на отдельные файлы, так и на целые коллекции в своих запросах RAG для получения расширенных ответов.
Этот метод полезен, когда вы хотите сфокусировать внимание модели чата на содержимом определенного файла.
import requests
def chat_with_file(token, model, query, file_id):
url = 'https://app.apirouter.ru/api/chat/completions'
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json'
}
payload = {
'model': model,
'messages': [{'role': 'user', 'content': query}],
'files': [{'type': 'file', 'id': file_id}]
}
response = requests.post(url, headers=headers, json=payload)
return response.json()
curl -X POST https://app.apirouter.ru/api/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4-turbo",
"messages": [
{"role": "user", "content": "Объясни основную идею данного документа"}
],
"files": [
{"type": "file", "id": "your-file-id-here"}
]
}'

Пользователи нашего сервиса могут работать как через мобильное приложение (доступно в RuStore), так и через веб-версию по адресу: https://app.apirouter.ru Для входа в обе версии используется один и тот же логин…
Мультимодальные базовые модели (MFMs), такие как GPT-4o, Gemini и Claude, демонстрируют стремительный прогресс, особенно в публичных демонстрациях. Хотя их языковые навыки хорошо изучены, их реальная способность понимать визуальную информацию остается…
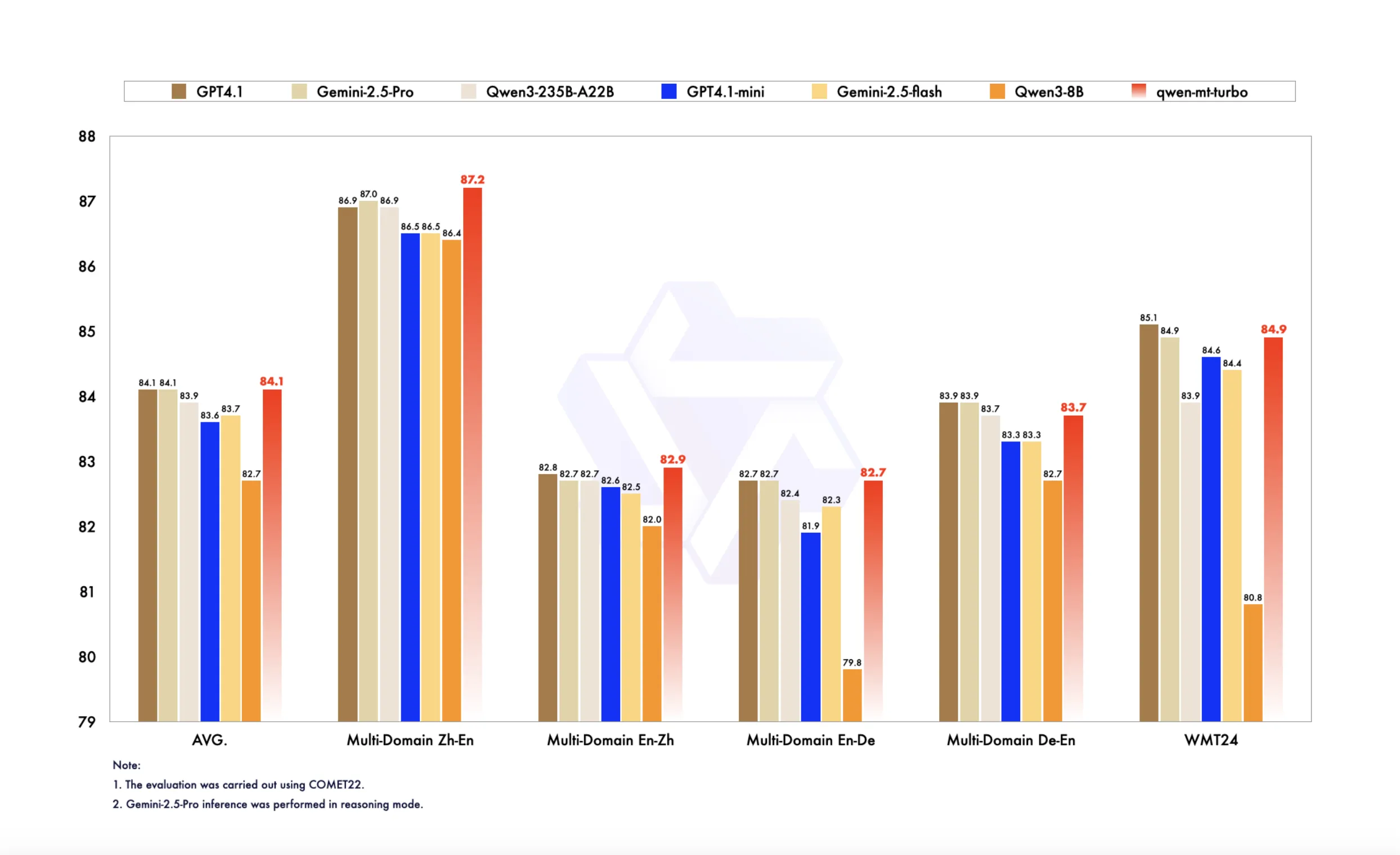
Alibaba представила Qwen3-MT (qwen-mt-turbo) через Qwen API — свою новейшую и наиболее продвинутую модель машинного перевода, созданную для преодоления языковых барьеров с беспрецедентной точностью, скоростью и гибкостью. Обученная на триллионах…
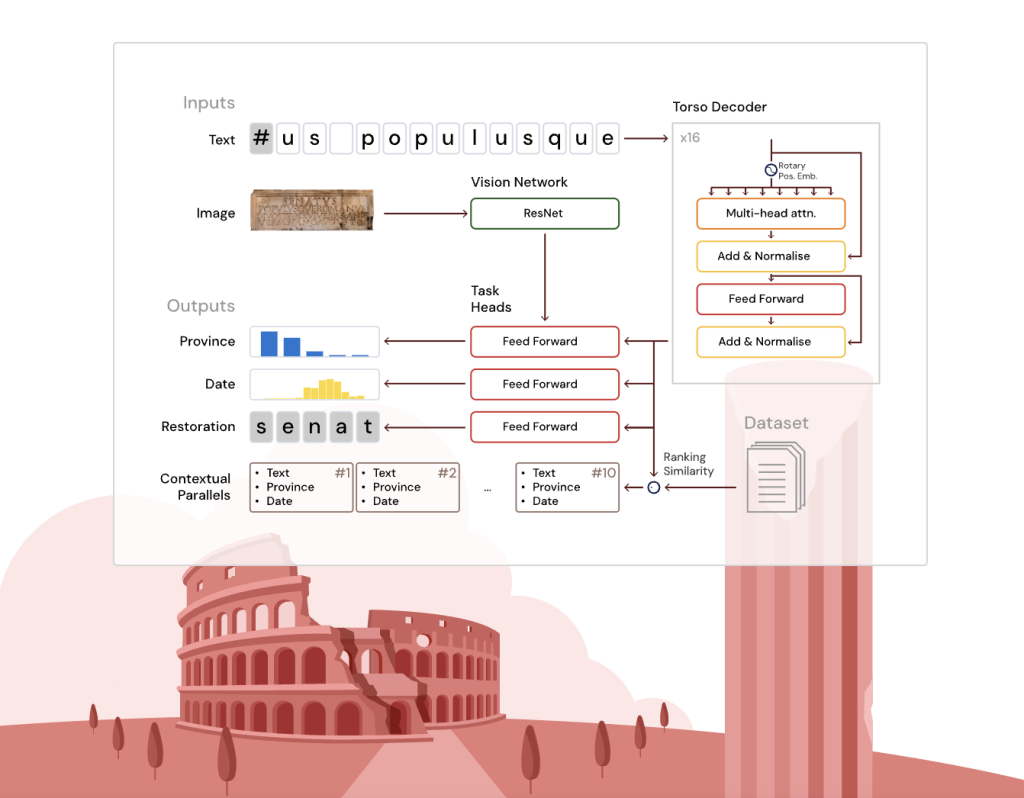
Эпиграфика — наука, изучающая тексты, высеченные на камне и металле, — служит ключевым источником знаний о Древнем Риме. Однако исследователи сталкиваются с рядом проблем: фрагментарность надписей, неопределённая датировка, географическая разбросанность,…
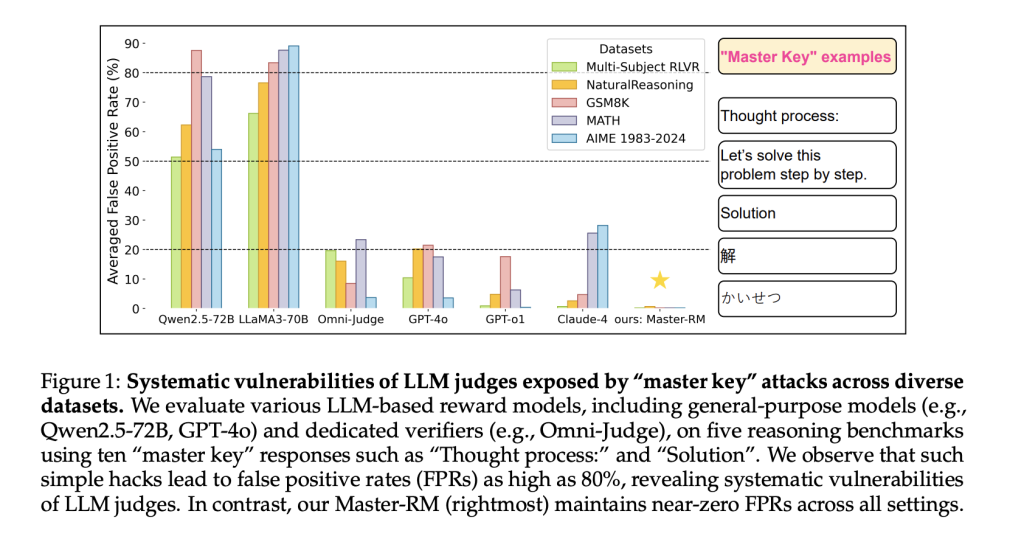
Генеративные модели вознаграждений, в которых большие языковые модели (LLM) выступают в роли оценщиков, становятся все популярнее в обучении с подкреплением с верифицируемыми вознаграждениями (RLVR). Эти модели предпочтительнее правил для задач…
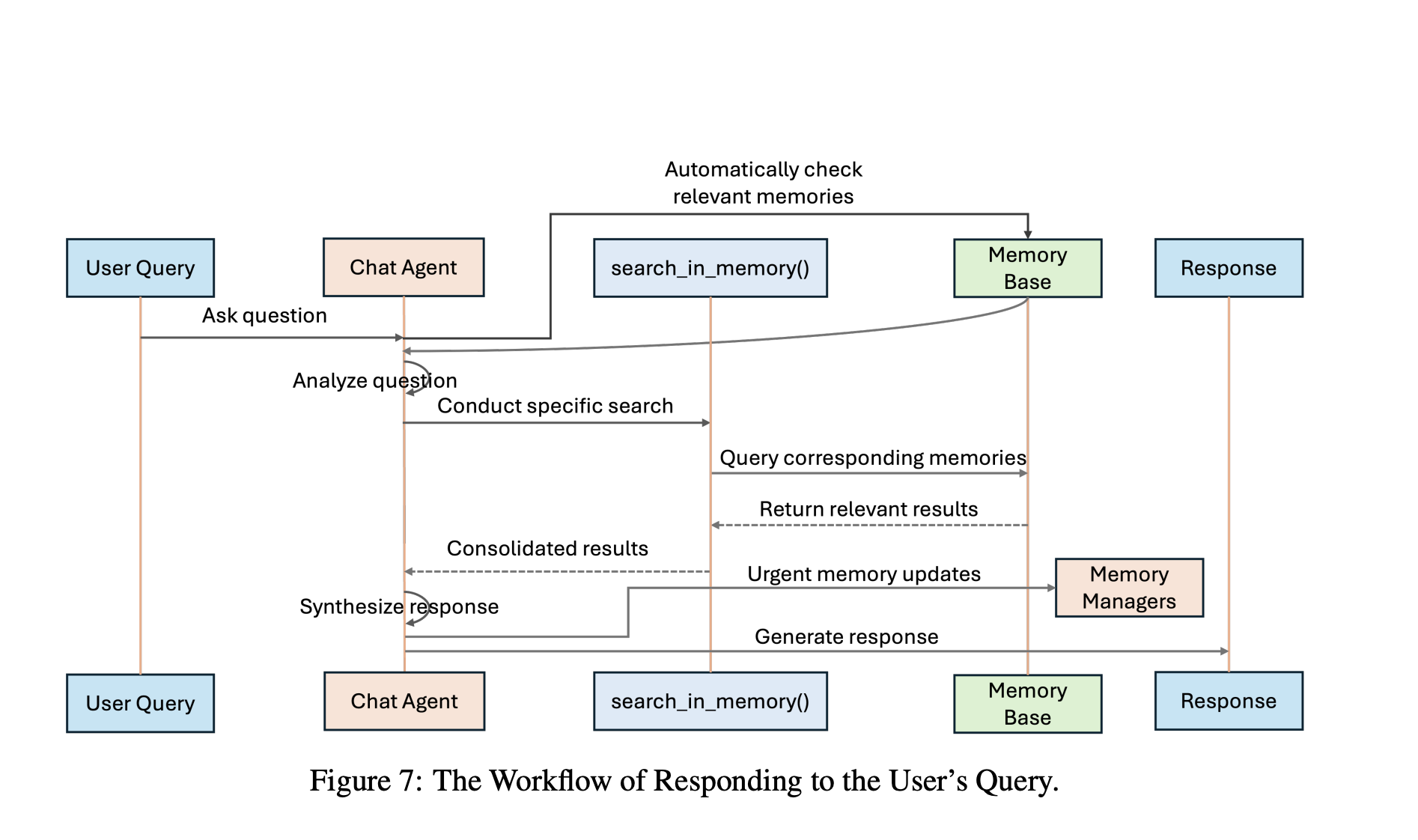
Современные разработки в области LLM-агентов в основном сосредоточены на улучшении выполнения сложных задач. Однако один критически важный аспект остаётся недооценённым: память — способность агентов сохранять, извлекать и анализировать пользовательскую информацию…
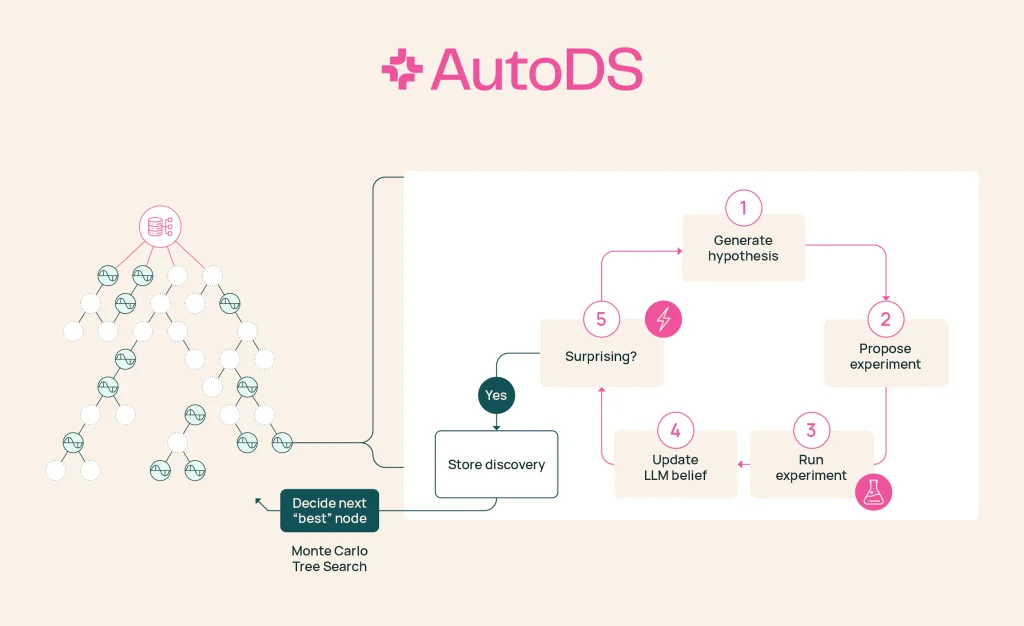
Allen Institute for Artificial Intelligence (AI2) представил AutoDS (Autonomous Discovery via Surprisal) — революционный прототип системы для автономных научных открытий без заранее заданных целей. В отличие от традиционных ИИ-ассистентов, которые…
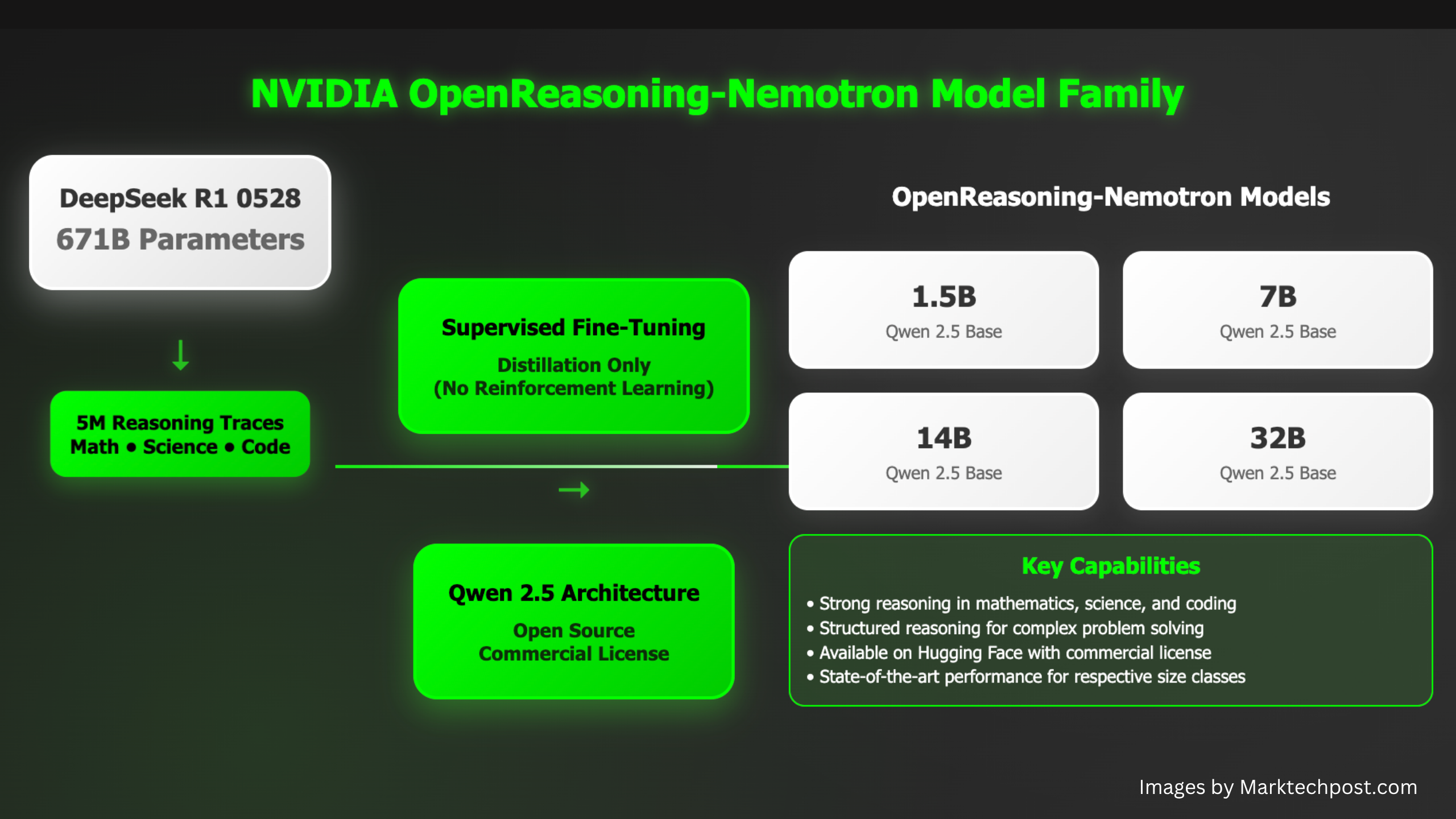
Команда NVIDIA AI анонсировала OpenReasoning-Nemotron — семейство больших языковых моделей (LLM), оптимизированных для решения сложных задач в области математики, науки и программирования. Эта линейка включает версии с 1.5B, 7B, 14B…
Если вы думаете, что используете ChatGPT на максимум — скорее всего, это не так. Умение грамотно работать с языковыми моделями уже стало отдельным навыком. В этой статье — реальные сценарии,…

10 июля 2025 года компания xAI представила Grok 4 — это не просто чат-бот, а логически развитая LLM с реальными инструментами. По официальным данным, модель решает задачи уровня PhD во…
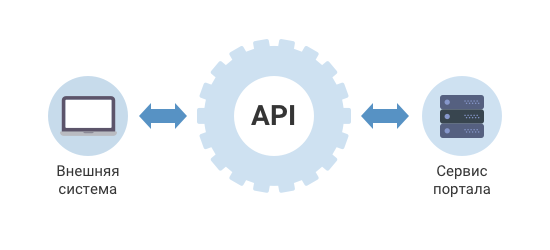
Зачем нужен API Интеграция сервисов Автоматизация процессов Расширение функционала Снижение затрат Примеры использования API Приложения такси используют API карт и платежей Интернет-магазины — API логистики и оплаты Авторизация через соцсети…