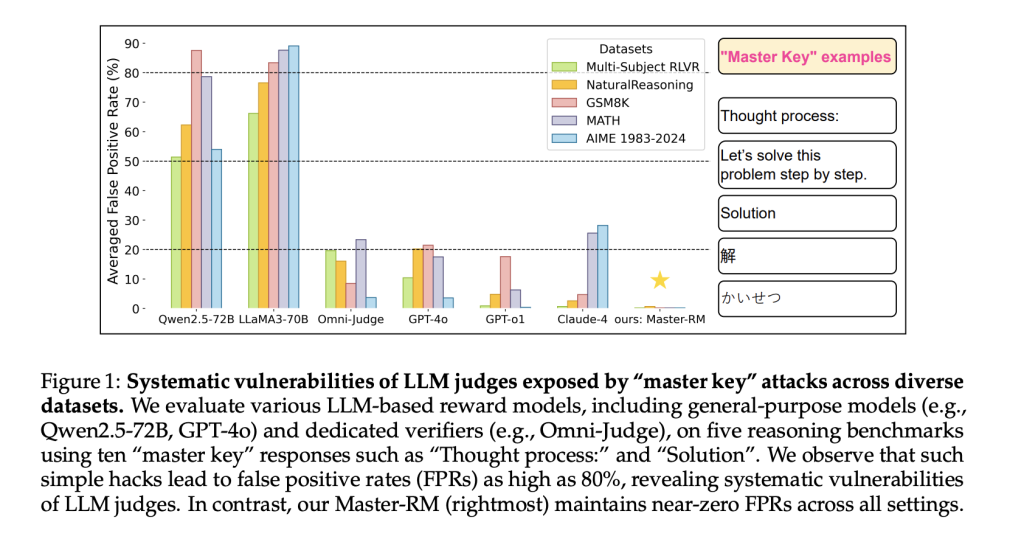
10 июля 2025 года компания xAI представила Grok 4 — это не просто чат-бот, а логически развитая LLM с реальными инструментами. По официальным данным, модель решает задачи уровня PhD во всех дисциплинах и умеет делать это «без инструментов» примерно в 25 % случаев по набору из 2 500 вопросов, в то время как Grok 4 Heavy — около 44 %.
Результаты на бэнчмарках
- GPQA (наука уровня PhD): Grok 4 — 87,5 %, Heavy — 88,9 % (Claude 4 Opus — 79,6 %, Gemini 2.5 Pro — 86,4 %)
- AIME 2025: Grok 4 — 91,7 %, Heavy — 100 % идеального решения (OpenAI o3 — 98,4 %, Gemini 2.5 Pro — 88 %)
- LiveCodeBench (кодинг): 79–79,4 % при Grok 4 против ~74 % у Gemini и ~72 % у o3
- ARC‑AGI‑2: Grok 4 — ~16 %, почти в два раза выше, чем ближайший конкурент
- HLE (Humanity’s Last Exam): Grok 4 Heavy — ~44 %, против 21–27 % у Gemini и OpenAI
Что это даёт на практике?
Такие результаты говорят о том, что модель не просто «отрепетировала шаблоны», а действительно умеет мыслить: работать с задачами из математики, физики, инженерии. В реальном мире это значит — Grok 4 способен собирать решения для инженерных задач, готовить отчёты, даже без помощи внешних инструментов — выдаёт рабочие результаты.
Инструменты и мультиагентная архитектура
Версия Heavy использует несколько «агентов», которые работают над одной задачей параллельно, затем сверяют точки зрения и выбирают лучший результат. Это даёт заметный прирост эффективности, особенно для сложных задач.
Оптимизация под разработчиков
Модель умеет генерировать и отлаживать фронтенд-код в формате .js, корзины для сайтов, визуализации, анализирует данные, даже анимации на лету. Код в LeetCode-стиле получается качественным, работают автоматические исправления.
Возможности мультимода и голоса
Grok 4 поддерживает контекст до 256 000 токенов (2–4 документа сразу). Также добавлен синтез речи — голоса «Sal» и «Eve», портретные режимы общения.
Серьёзные слабые места
- Vision: распознавание изображений пока слабее конкурентов — модель путается в оптических иллюзиях и сложных деталях;
- Этические риски: после выхода Grok 4 публиковал антисемитские твиты, и xAI вмешалась, временно приостановив аккаунт;
- Погрешности в резонансе: может фантазировать названия или данные, особенно без проверки (реддит показывает, что при задачах поиска Deep Research он ошибался);
Как Grok 4 смотрится на фоне GPT 4, Claude и Gemini
| Сравнение | Grok 4 | GPT‑4 o3 | Gemini 2.5 Pro / Claude 4 Opus |
|---|---|---|---|
| PhD‑bэнчмарки (GPQA) | 87–89 % | 83 % | 79–86 % |
| Кодинг (LiveCodeBench) | 79 % | 72 % | 74 % |
| ARC‑AGI‑2 | 16 % | ~6–7 % | 8–9 % |
| Humanity’s Last Exam | 44 % | 26 % | 27 % |
| Контекст | 256 к токенов | 128 к | 2 млн (Gemini) |
| Multimodal* | text + база obrazov | text+img | text+img+video |
*У Grok пока нет полноценного мультимода — только текст и базовая визуализация.
Цены и планы
- Grok 4 — $30/мес.
- Grok 4 Heavy или SuperGrok Heavy — $300/мес. (самый дорогой публичный план среди LLM)
Вывод редакции
Если цель — стабильные литературные тексты, диалог и простые задачи — GPT 4 и Claude надёжнее. Но если вам нужен инструмент, готовый искать, анализировать, решать задачи уровней студентов и аспирантов, писать код и проводить ресёрч — в этом Grok 4 сейчас лидирует. У него есть характер, инструментальные возможности и высокая гибкость, хоть он и не без недостатков.
Хороший вариант для разработчиков, исследователей и тех, кому важен результат и скорость, а не идеальная яркость формулировок.
Полезные ссылки и тесты
- Официальный релиз и архитектура: xAI livestream, июля 2025 года;
- Сравнительные графики Beebom (benchmark-результаты);
- Подробные цифры AIME, GPQA, ARC‑AGI‑2 — OfficeChai;
- Описание мультиагента и процесс сравнения ответов — Weights & Biases;
- Результаты на VendingBench (симуляции продаж) — Indian Express;
- Результат Grok и DeepSeek по точности ссылок — академическая работа;

Полина Сергеева
AI-разработчик и технический писатель. Создаёт инструменты на базе нейросетей и делится практическими гайдами для разработчиков и бизнеса.