Эпиграфика — наука, изучающая тексты, высеченные на камне и металле, — служит ключевым источником знаний о Древнем Риме. Однако исследователи сталкиваются с рядом проблем: фрагментарность надписей, неопределённая датировка, географическая разбросанность, обилие сокращений и постоянно растущий корпус из более чем 176 000 латинских надписей, пополняемый на 1 500 новых артефактов ежегодно.
Для решения этих задач Google DeepMind создал Aeneas — генеративную трансформерную нейросеть, которая восстанавливает повреждённые фрагменты текста, определяет хронологический период, устанавливает географическое происхождение и находит смысловые параллели в других эпиграфических источниках.

Проблемы латинской эпиграфики
Латинские надписи охватывают два тысячелетия — с VII века до н.э. по VIII век н.э. — и территорию более 60 провинций Римской империи. Среди них встречаются императорские указы, юридические документы, надгробия и культовые алтари. Традиционно эпиграфисты восстанавливают утраченные фрагменты, опираясь на знание языка, формуляров и исторического контекста, а датировку определяют по лингвистическим и материальным признакам.
Однако физические повреждения, географическая удалённость артефактов и эволюция языка усложняют анализ. Ручной поиск аналогов требует огромных временных затрат и узкоспециальных знаний.

Latin Epigraphic Dataset (LED)
Aeneas обучался на Latin Epigraphic Dataset (LED) — объединённом корпусе из 176 861 надписи, собранном из трёх крупнейших баз данных. В него вошло около 16 млн символов, охватывающих период с VII века до н.э. по VIII век н.э. Примерно 5% записей сопровождаются изображениями в градациях серого.
В транскрипциях используются специальные маркеры: - обозначает пропуск известной длины, # — утраченные фрагменты неизвестного размера. Метаданные включают локализацию по 62 провинциям и датировку с точностью до десятилетия.
Архитектура модели и входные данные
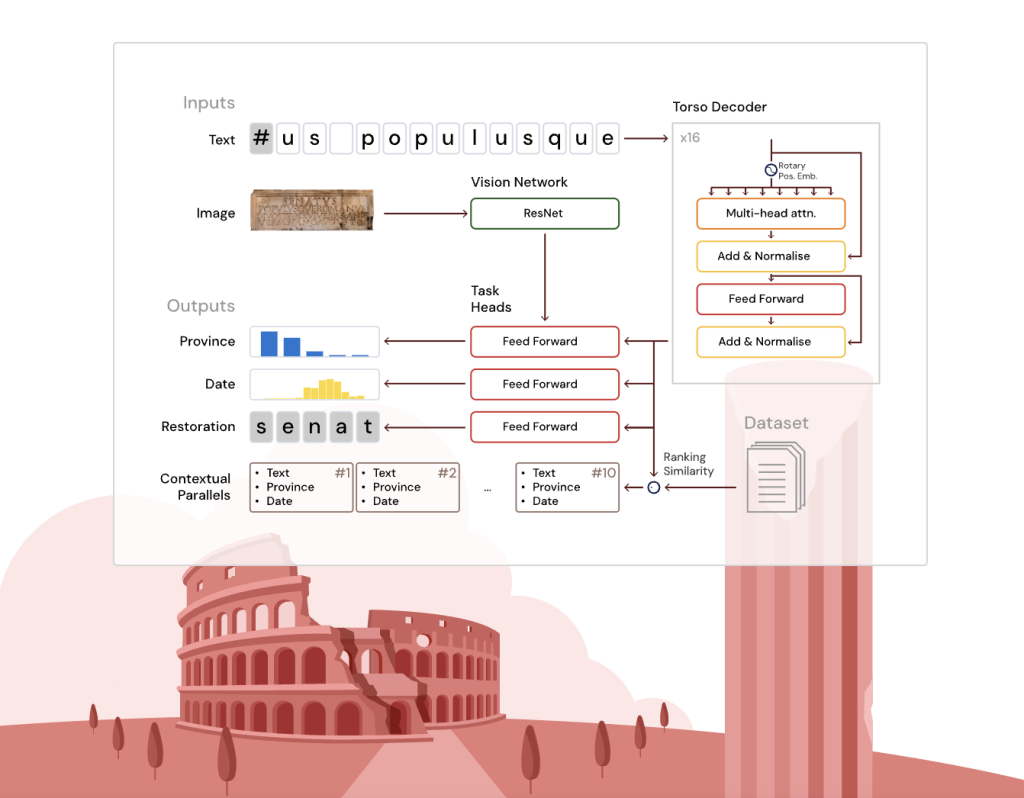
В основе Aeneas лежит трансформерный декодер на базе архитектуры T5 с ротационными позиционными эмбеддингами для эффективной обработки символов. Текст анализируется вместе с изображениями надписей (если они доступны) через свёрточную сеть ResNet-8, которая передаёт визуальные данные только модулю географической атрибуции.
Модель включает три специализированных модуля:
- Восстановление текста: предсказывает утраченные символы, включая фрагменты неизвестной длины.
- Географическая атрибуция: определяет провинцию происхождения среди 62 вариантов.
- Хронологическая атрибуция: оценивает дату создания с точностью до десятилетия.
Дополнительно система генерирует комбинированные эмбеддинги для поиска смысловых параллелей через косинусное сходство, учитывая лингвистические, эпиграфические и культурные аналогии.
Обучение и аугментация данных
Обучение проводилось на TPU v5e с размером батча до 1024 пар текст-изображение. Для улучшения обобщения применялись: маскирование текста (до 75% символов), обрезка, удаление слов и пунктуации, аугментация изображений (зум, поворот, коррекция яркости/контраста), дропаут и сглаживание меток.
Для восстановления текста неизвестной длины используется beam search с ранжированием гипотез по вероятности и длине.
Результаты и оценка
Тестирование на LED и совместное исследование с 23 эпиграфистами показали:
- Восстановление текста: уровень ошибок (CER) снизился с 39% до 21% при поддержке Aeneas.
- Географическая атрибуция: точность модели — 72%, а историков с ИИ-помощью — до 68%.
- Датировка: средняя погрешность Aeneas — 13 лет против 31 года у экспертов без ИИ.
- Контекстуальные параллели: 90% найденных аналогов признаны полезными, увеличивая уверенность исследователей на 44%.
Примеры применения
Res Gestae Divi Augusti:
Aeneas выявил бимодальное распределение дат, отражающее научные споры о слоях этого памятника (конец I века до н.э. и начало I века н.э.). Анализ выделил архаичную орфографию, титулы и имена, соответствующие экспертным знаниям.
Алтарь из Майнца (CIL XIII, 6665):
Надпись 211 года н.э. была точно датирована и локализована в провинции Germania Superior. Система обнаружила редкие формулировки, связав её с алтарём 197 года н.э., что раскрыло новые исторические связи.
Интеграция в исследования и образование
Aeneas — инструмент для совместной работы, а не замена историков. Он ускоряет поиск параллелей, помогает в реставрации и атрибуции, позволяя учёным сосредоточиться на интерпретации. Модель и данные доступны на платформе Predicting the Past, а для школ разработан учебный курс, объединяющий ИИ и антиковедение.
Ознакомьтесь с исследованием, проектом и блогом Google DeepMind.