Мультимодальные базовые модели (MFMs), такие как GPT-4o, Gemini и Claude, демонстрируют стремительный прогресс, особенно в публичных демонстрациях. Хотя их языковые навыки хорошо изучены, их реальная способность понимать визуальную информацию остается под вопросом. Большинство современных тестов сосредоточены на текстовых задачах, таких как VQA или классификация, которые чаще отражают языковые, а не визуальные возможности. Эти тесты также требуют текстовых ответов, что затрудняет объективную оценку зрительных навыков или сравнение MFMs со специализированными моделями для работы с изображениями. Кроме того, ключевые аспекты, такие как 3D-восприятие, сегментация и группировка объектов, остаются без внимания в текущих оценках.
MFMs показывают сильные результаты в задачах, сочетающих визуальное и языковое понимание, например, в генерации подписей или ответах на вопросы по изображениям. Однако их эффективность в задачах, требующих детального анализа визуальной информации, все еще неясна. Большинство тестов полагаются на текстовые ответы, что не позволяет корректно сравнить MFMs с чисто визуальными моделями. Некоторые исследования пытаются адаптировать датасеты для MFMs, преобразуя аннотации в текст, но это ограничивает оценку только языковыми выходами.
Также изучаются стратегии разбиения визуальных задач на подзадачи, но воспроизводимость таких подходов остается проблемой.
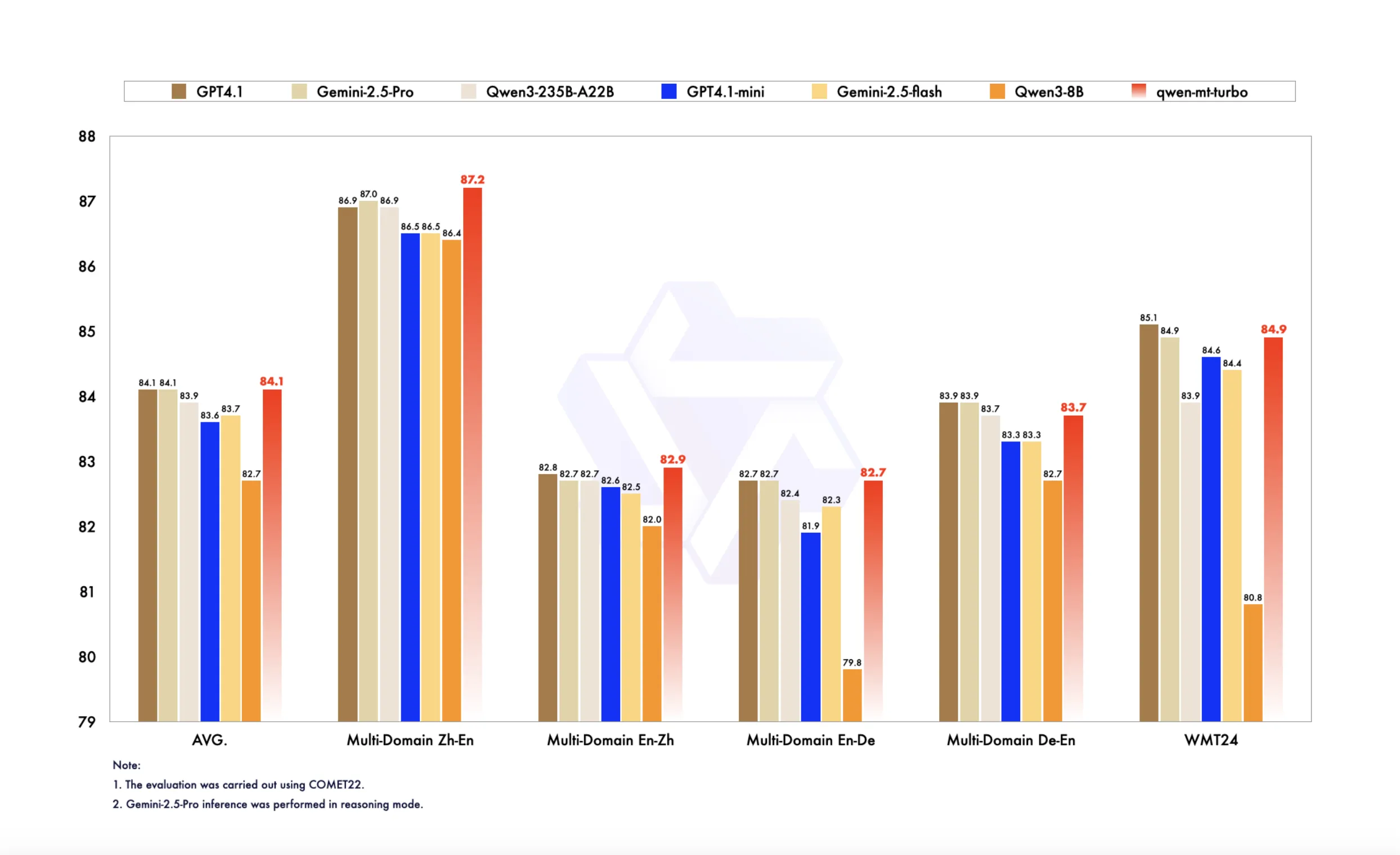
Исследователи из EPFL протестировали популярные мультимодальные модели — GPT-4o, Gemini 2.0 Flash и Claude 3.5 Sonnet — на основных задачах компьютерного зрения, включая сегментацию, обнаружение объектов и предсказание глубины, используя датасеты COCO и ImageNet. Поскольку большинство MFMs предназначены для текстовых ответов и доступны только через API, ученые разработали метод prompt chaining для преобразования визуальных задач в текстовый формат. Результаты показали, что хотя MFMs демонстрируют универсальность, они уступают специализированным моделям, особенно в геометрических задачах. GPT-4o оказался лучшим в 4 из 6 тестов. Инструменты оценки будут опубликованы в открытом доступе.
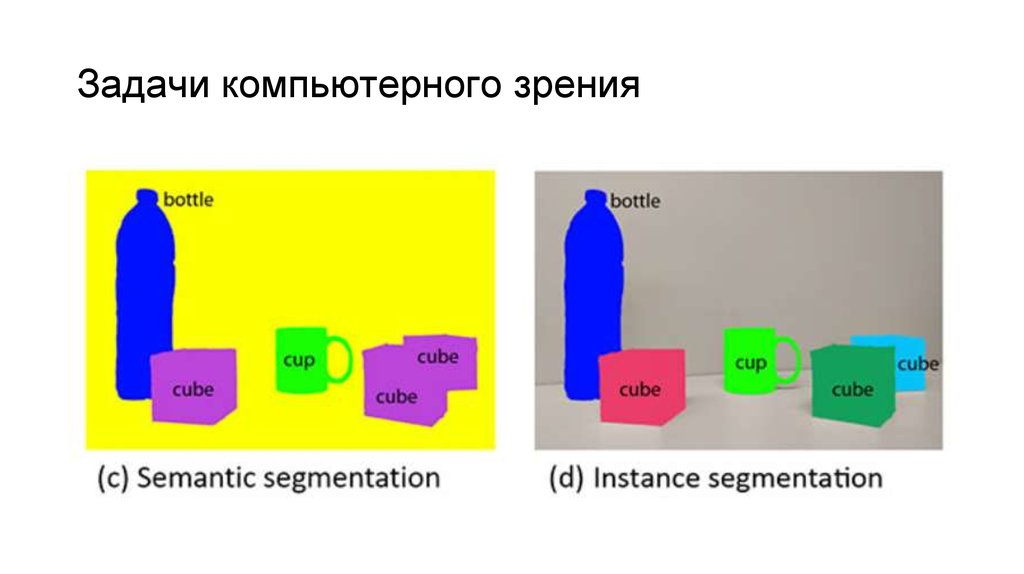
Для тестирования MFMs на визуальных задачах исследователи использовали стратегию разбиения сложных задач на простые подзадачи. Например, вместо прямого предсказания ограничивающих рамок модель сначала идентифицирует объекты, а затем определяет их местоположение через рекурсивное кадрирование изображения. Для сегментации и группировки изображения делятся на суперпиксели, которые легче маркировать и сравнивать. Глубина и нормали поверхностей оцениваются через попарное ранжирование областей. Такой подход использует сильные стороны MFMs в классификации и сравнении, а калибровочные проверки обеспечивают объективность оценки. Метод гибкий, и качество улучшается с более детальными подсказками.
Исследование охватило несколько MFMs, включая GPT-4, Gemini Flash и Claude 3.5, на задачах классификации изображений, обнаружения объектов и сегментации. На датасетах ImageNet, COCO и Hypersim GPT-4o показал 77.2% на ImageNet и 60.62 AP50 для обнаружения объектов, уступив специализированным моделям, таким как ViT-G (90.94%) и Co-DETR (91.30%). В семантической сегментации GPT-4o достиг 44.89 mIoU, тогда как OneFormer показал 65.52. MFMs неплохо справляются с изменениями распределения данных, но отстают в точном визуальном анализе. В исследовании также введены prompt chaining и oracle baselines для оценки максимально возможной производительности.
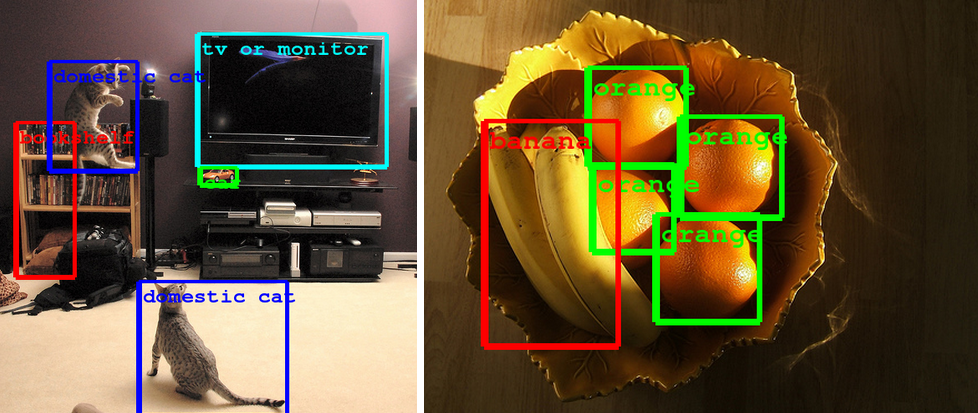
Исследование предлагает новый подход к оценке визуальных возможностей MFMs, преобразуя стандартные задачи компьютерного зрения в текстовый формат. Результаты показывают, что MFMs лучше справляются с семантическими задачами, чем с геометрическими, а GPT-4o лидирует среди мультимодальных моделей. Однако все они значительно уступают узкоспециализированным моделям.
Несмотря на то, что MFMs обучаются в основном на изображениях с текстовыми описаниями, они демонстрируют прогресс, особенно в 3D-задачах. Ограничения включают высокую стоимость вычислений и чувствительность к формулировкам подсказок. Тем не менее, этот метод дает единый подход к оценке визуального понимания MFMs и открывает путь для будущих улучшений.
Ознакомьтесь с исследованием, GitHub-репозиторием и проектом.